
프로젝트에 대한 소개
프로젝트 주제를 1 문장으로 표현하면?
원하는 전기차 충전소를 편하게 찾을 수 있는 서비스
or
실시간 전기자동차 충전소 지도
및 사용 통계 조회 서비스
어떤 문제를 해결하려고 이 프로젝트가 시작되었는가?
전기차 충전소가 너무 많은데, 사용자가 진짜 원하는 조건의 충전소를 찾기 어려워요
사용자가 필요로 하는 정보가 생각보다 많은데, 이 부분을 보기 편하게 만들어준 웹이나 앱이 거의 없습니다.
사용자가 원했던 정보들은 이런 것들이 있었는데요
- 충전기의 타입을 알고 싶어요
- 급속, 완속 이라고 하는 충전 방식에 따라 충전 속도가 달라지고, 배터리 수명이 달라집니다.
- 충전기 타입이 많아서 어댑터가 없는 경우라면 특정 타입의 충전기만 사용할 수 있습니다
- 충전소마다 혜택이 달라요
- 특정 충전소에서만 혜택을 받을 수 있는 경우가 많아서, 혜택을 받기 위해서는 특정 충전소로 가야 합니다
- 이 충전소에 가면 얼마나 혼잡할지를 모르겠어요
- 1개의 앱에서만 과거 2~3일 정도의 데이터를 보여줄 뿐, 특정 요일에 특정 시간은 어떤 상황일지를 알 수 없어요
이런 3가지 큰 정보를 제공해 주면 저희 서비스를 사용할 것이라는 가설로부터 시작한 프로젝트입니다
프로젝트에서 기술적으로 고민해 볼 만한 포인트
사실 이 프로젝트의 기능은 정말 간단한 편입니다.
평범한 CRUD에 조회 조건이 좀 있는 정도로 끝이 납니다.(아직 초기라서 이런 여유로운 생각을 할 수 있는 거긴 합니다)
대용량 데이터를 어떻게 다뤄볼 수 있을까?
초반 단계에서 고민해야 할 모든 문제는 대용량 데이터라는 점에서 생기게 됩니다
일단 전국에 충전기가 22만 개 이상, 충전소가 6만 개 이상 존재하게 됩니다.
일단 이 충전기에 대한 데이터를 저장하는 것만으로 22만 개의 row를 가진 테이블이 등장하게 됩니다.
여기에 사용자가 원할 것으로 생각하는 3번째 데이터가 섞이는 순간 문제가 복잡해집니다.
요일별로 데이터를 저장하려고 하면 22만*7 = 154만 개의 row 가 테이블에 나오게 됩니다.
시간별로 데이터를 저장하려고 하면 154만*24 = 3696만 개의 row 가 한 테이블에 나오게 됩니다.
물론 매 시간마다 데이터를 저장하지 않는 것부터 시작을 할 테니 초기에는 훨씬 적은 데이터로 시작할 예정입니다.
단순히 저장을 하고, 조회만이 아니라, 시간대별로 데이터가 바뀌니 업데이트 주기마다 22만 개의 row 가 바뀌는 상황이기도 합니다.
내가 이번 프로젝트에서 얻어가고 싶은 경험
대용량 데이터를 다뤄보는 경험
당연하지만 대용량 데이터는 실무를 경험하지 않는다면 얻을 수 없는 경험일 것 같았는데, 이번 기회에 다뤄보면서 index를 걸었을 때 성능이 어떻게 변화하는지나, 여러 가지 시도들을 통해서 최적화를 하는 과정을 경험해보고 싶습니다
한 명의 개발자가 아닌 팀원으로 프로젝트를 진행해 보는 경험
지금까지의 프로젝트에서는 한 명의 개발자로 각자의 기능을 개발해 왔다고 생각합니다.
물론 그런 것도 좋지만, 이번에는 조금 더 팀을 고려하면서, 팀원으로 프로젝트를 해보려고 합니다.
1주 차에 했던 일
처음에 기획을 모두가 이해하는 일을 진행했습니다.
왜 이 프로젝트가 진행되었는지를 다 같이 이해하고, 도메인에 대한 정보를 모두가 함께 얻는 시간을 가졌습니다
프로젝트 세팅 과정을 거쳤습니다
프로젝트에서 사용하는 라이브러리는 아래와 같습니다
- jpa
- jpa는 orm으로, 레벨 2 까지는 jdbc를 통해서 sql을 직접 작성해 왔지만, 직접 sql을 작성해서 물론 코드를 짤 수 있지만, oneToMany 같은 매핑 과정이 매우 힘든 상황입니다, 이를 편하게 할 수 있습니다
- 객체 그래프를 마음껏 탐색할 수 있습니다. 기존 도메인에서 sql 을 통해 탐색했을 경우에, NPE 가 발생하기 쉽지만, 이 부분을 지연 로딩을 통해 해결할 수 있습니다
- 대용량 데이터를 다루는데, 이 과정에서 성능 문제가 발생할 경우 아쉽지만 보내줘야 할 수도 있긴 합니다
- flyway
- 처음 단계에서 바로 적용할 필요는 없지만, 미리 테이블을 형상관리 하기 시작하면, 나중에 적용했을 때, 시간이 훨씬 적게 걸린다는 점이 컸습니다. 물론 이래도, 처음에 시작할 때 바로 적용하는 것은 힘들겠죠
- db를 분리하게 되면, 로컬 db, 개발 서버(테스트 서버) db, 라이브 db에 각각의 스키마를 맞춰주는 과정이 필요한데, 이 과정을 편하게 할 수 있도록 해주는 장점이 명확해서 사용해보려고 합니다
- h2 (test 환경에서 사용)
- 실제 프로덕션에 mysql을 사용하지만, h2 를 테스트로 사용했을 때, 아래와 같은 장점이 있습니다 아래의 sql 을 첫 줄에 삽입해서, table을 truncate 시키는 명령어를 test db에서만 동작하도록 강제할 수 있습니다
SELECT H2VERSION() FROM DUAL;
- mysql
- 일단 자료가 많고, mysql에 대해서 학습했던 경험이 있기에, 기존에 있던 경험을 활용할 수 있어서 사용하게 되었습니다.
- 공간 데이터베이스를 지원합니다. POINT 나, ST_Distance를 통해 거리를 측정할 수 있습니다 (추후에 postgresql로 변경해 성능 체크를 해볼 계획입니다)
- restdocs
- swagger를 사용했을 때, 최신화를 시키지 못했던 경험이 있는 것 같아서, 이 부분을 해결하고자, 테스트코드 기반으로 사용하는 restdocs를 사용하기로 정했습니다
- jasypt
- 도메인상, api 키를 관리해야 하는데, 그때마다 환경변수에 추가하는 것보다, 암호 키를 통해서 키를 암호화할 수 있다면, 환경변수 추가하는 작업이 없어져서 편할 것 같아서 도입하게 되었습니다
- git submodule 보다 적용 방식이 간단해서 적용하게 되었습니다
어쩌다 보니 프로젝트에서 중요한 일을 맡게 되었다
과거에 프로젝트 경험도 어느 정도 있고, 여러 가지 상황을 고려하는 일을 되게 잘하는 편이다 보니, 어쩌다 보니 프로젝트를 리드하는 역할과 비슷하게 맡게 된 것 같습니다
처음 하는 일이다 보니 정말 고민이 많이 되고, 잘못되었을 때 많이 미안할 것 같아서 어떻게 해야 될지 고민입니다
좋은 의견 있으신 분은 댓글로 달아주시면 아주 좋을 것 같아요
이 프로젝트에서 했던 일
- 기술을 선정한다
- 선정의 방식은 여러가지 기술을 나열하고, 각각의 장단점에 대해서 소개하고 선택을 할 수 있도록 만드려고 합니다.
- 취향의 영역에서는 팀원들의 의견을 반영합니다. 그랬던 상황으로는 swagger vs restdocc를 결정했던 일이 있었습니다(swagger에서 controller에 코드가 지저분해 보여서 restdocs 쪽이 좋아 보인다는 말을 듣고 결정하게 되었습니다
- 1명씩 매일매일 커피챗을 한다
- 궁금한 것들을 계속 물어보고 있기는 합니다.( ex) 나에게 바라는 점, 팀에게 바라는 점, 이 프로젝트에서 남겨갔으면 좋겠는 것, 이 프로젝트에서 하고 싶은 일)
- 데모데이까지 하면 좋아 보이는 기능을 정한다
- 어떤 기능을 넣으면 좋을지 같이 고미
- 특정 기술을 도입하면 좋아 보인다면, 그 기술을 정합니다
- 기술을 도입할 때, 같이 고민하면 좋은 포인트를 전달합니다
이 예시는 아래 사진들에서 볼 수 있습니다
배포 cd를 만든다면?

flyway를 적용한다면?
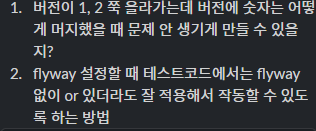
jasypt를 쓴다면?

물론 이 방식이 좋은 방법인지는 잘 모르겠습니다.
이 방법이 괜찮은지 팀원들과 주기적으로 커피챗을 하며, 체크해 볼 테니, 잘못되었다고 해도 금방 바로잡을 수 있겠죠.
코치님들에게도 자주자주 질문해 보면서 방향을 잡아보려고 합니다
정말 고민이 많이 되는 한 주였습니다.
'우아한테크코스' 카테고리의 다른 글
| "[DB] 대량의 데이터를 DB에 넣는 과정을 최적화해보자" (7) | 2023.07.05 |
|---|---|
| "pr 본문에 이슈 번호를 달아주는 기능을 만들었습니다" (0) | 2023.07.04 |
| DB 에 변경된 부분만 업데이트 하려면(feat Proxy 객체, 변경감지) (12) | 2023.05.16 |
| 레벨 인터뷰 스터디 (0) | 2023.05.07 |
| 레벨 인터뷰 스터디 준비 (0) | 2023.04.23 |