
문제 상황
같은 형태의 테이블 2개를 하나의 테이블로 합쳤을 때, Auto Increment 때문에 생길 수 있는 문제에 대해서 정리를 해보려고 합니다
편의를 위해서 정말 간단한 엔티티로 설명을 드리도록 하겠습니다
@NoArgsConstructor
@AllArgsConstructor
@Getter
@Entity
@Table(name = "transaction_data")
public class TransactionData {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String name;
public TransactionData(String name) {
this.name = name;
}
}이를 저장하는 코드는 다음과 같습니다
@RequiredArgsConstructor
@Service
public class TransactionDataService {
private final TransactionDataRepository transactionDataRepository;
public void save() {
var transactionData = new TransactionData(UUID.randomUUID().toString());
transactionDataRepository.save(transactionData);
}
}이 메서드를 통해서 저장을 하게 되면
아래와 같이 저장이 됩니다.
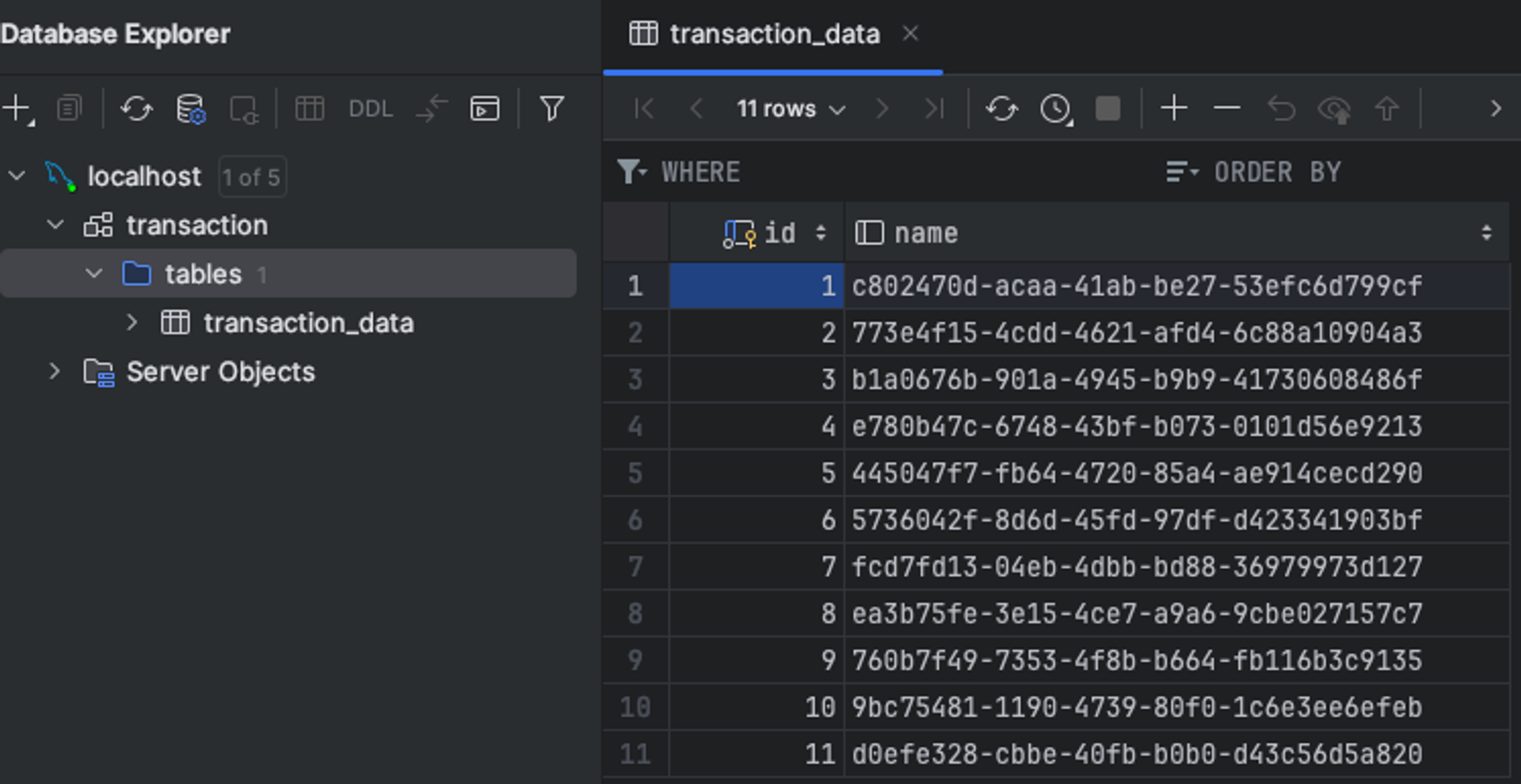
어느 날 다른 테이블의 데이터를 가져오라는 요구사항이 생겼습니다
그 데이터는 another_data라는 테이블입니다.
총 10개의 row 가 있는 transaction_data 와 같은 형태의 데이터인데요
column 이름은 편의를 위해서 모두 동일하게 만들었습니다
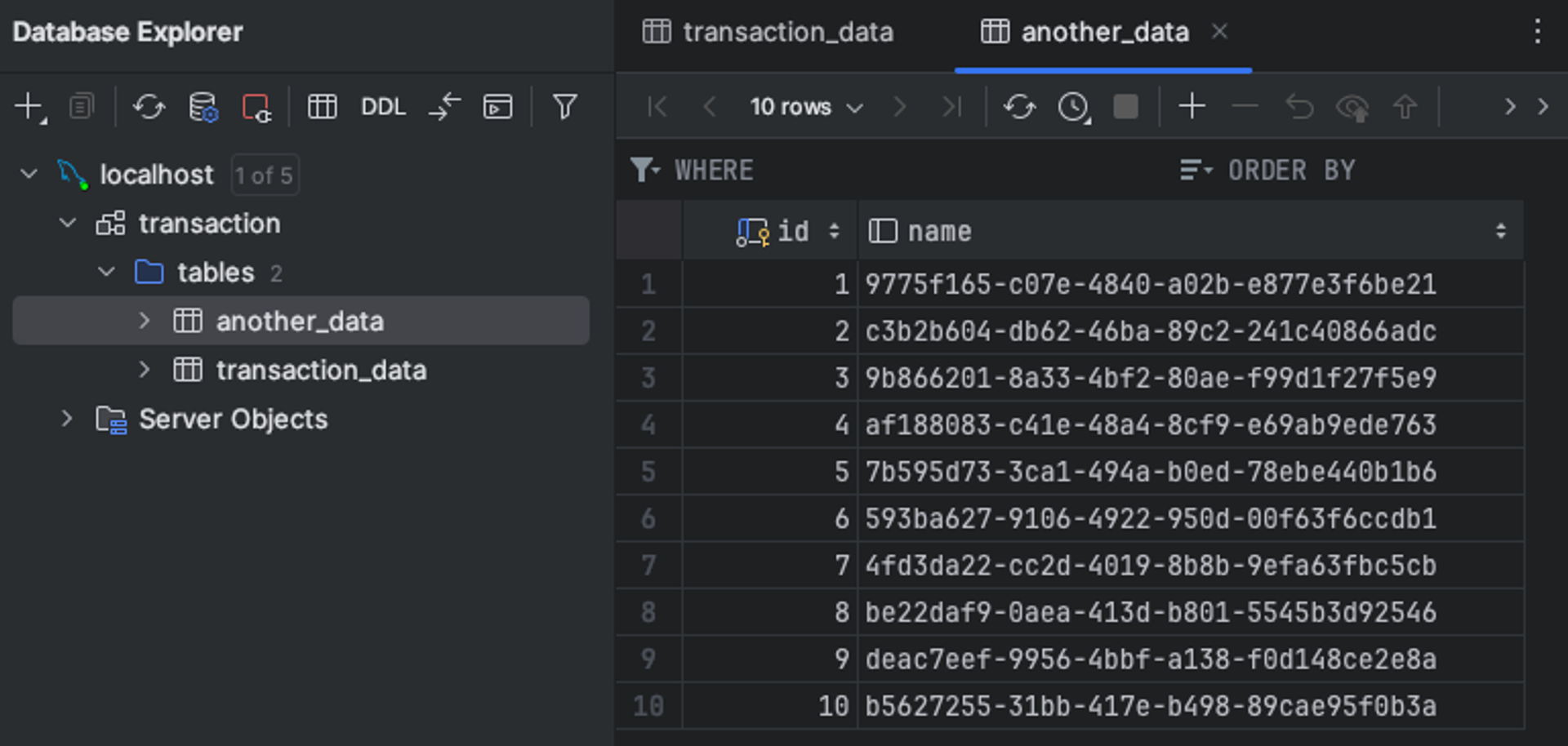
그냥 막 합쳐도 되지 않을까?
batch를 활용해서 another_data 테이블에서 데이터를 읽어오고, 그대로 transaction_data에 저장하면 되겠다라고 하면 큰일 납니다
중요한 데이터라면 바로 감옥에 갈 수도 있죠
문제의 원인은 another_data의 id와 transaction_data의 id 같다는 점입니다
id 가 겹치면, 기존 데이터가 덮어씌워지거나, 일부분의 데이터가 누락되게 됩니다.
처음 생각한 해결책
id 가 겹치는 것이 문제라면, 그만큼 여유분을 더해주고 시작하면 되겠다
트래픽이 오고 있어도, 200개 이상은 안될 테니 200개만큼의 여유분을 만들자
another_data의 id를 +200 해서, 1번을 201번으로, 2번을 202번으로 만들어서 transaction_data에 저장하자
저장이 다 끝나면 transaction_data의 id를 401부터 시작하도록 바꾸자
이렇게 작동하는 시나리오를 동작시켜 보도록 하겠습니다
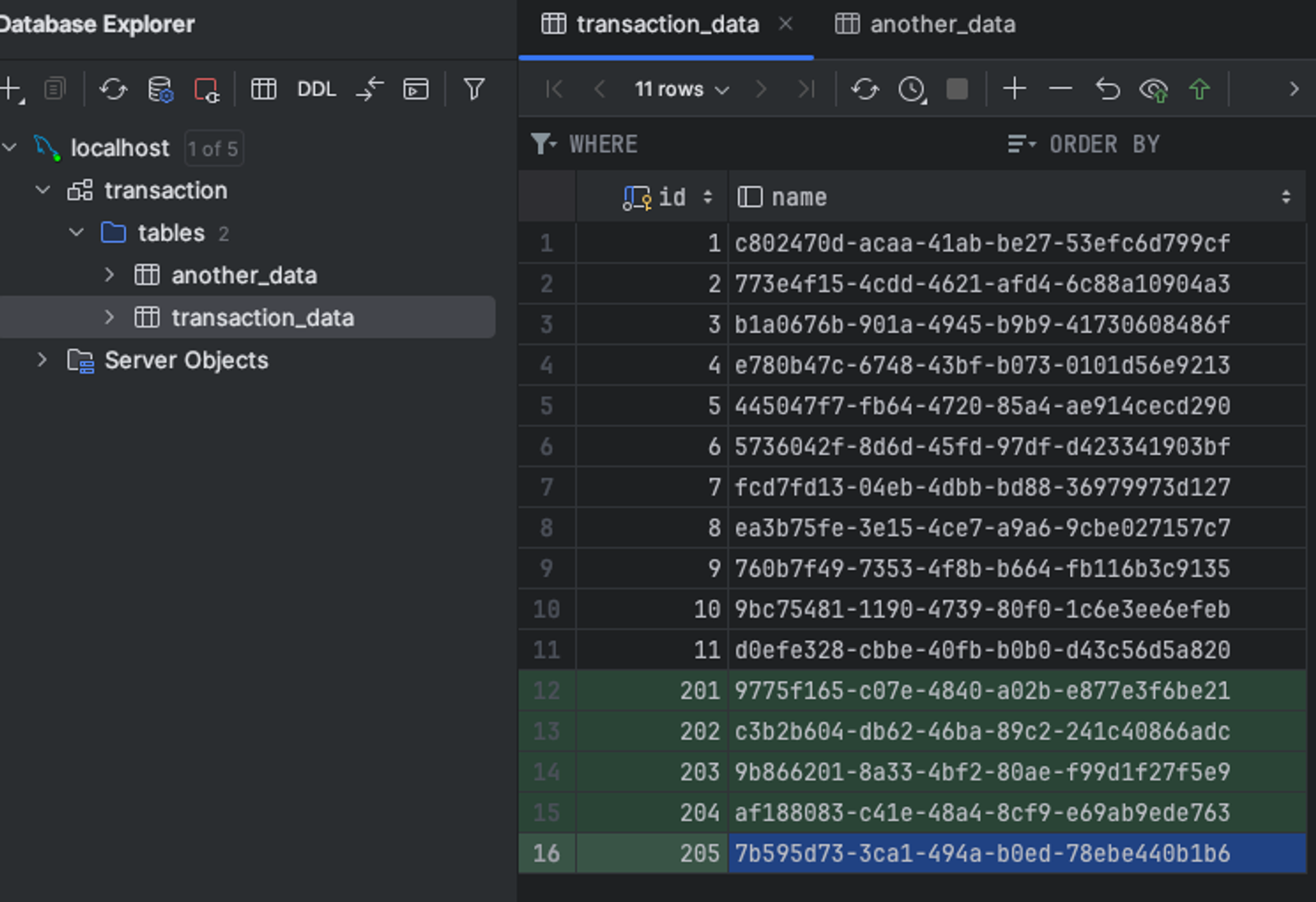
한 번에 모든 작업이 이루어질 수는 없기 때문에 조금씩 옮길 텐데요
위와 같이 5개가 옮겨진 상황이라고 해봅시다
이때 transaction_data 테이블에 1개 추가 요청이 들어오면 어떤 id를 사용하게 될까요?
원래 기존의 데이터가 쌓이는 11에 이어서 12로 시작할까요?
아니면 205까지 있는 상황에서 206에서 시작할까요?
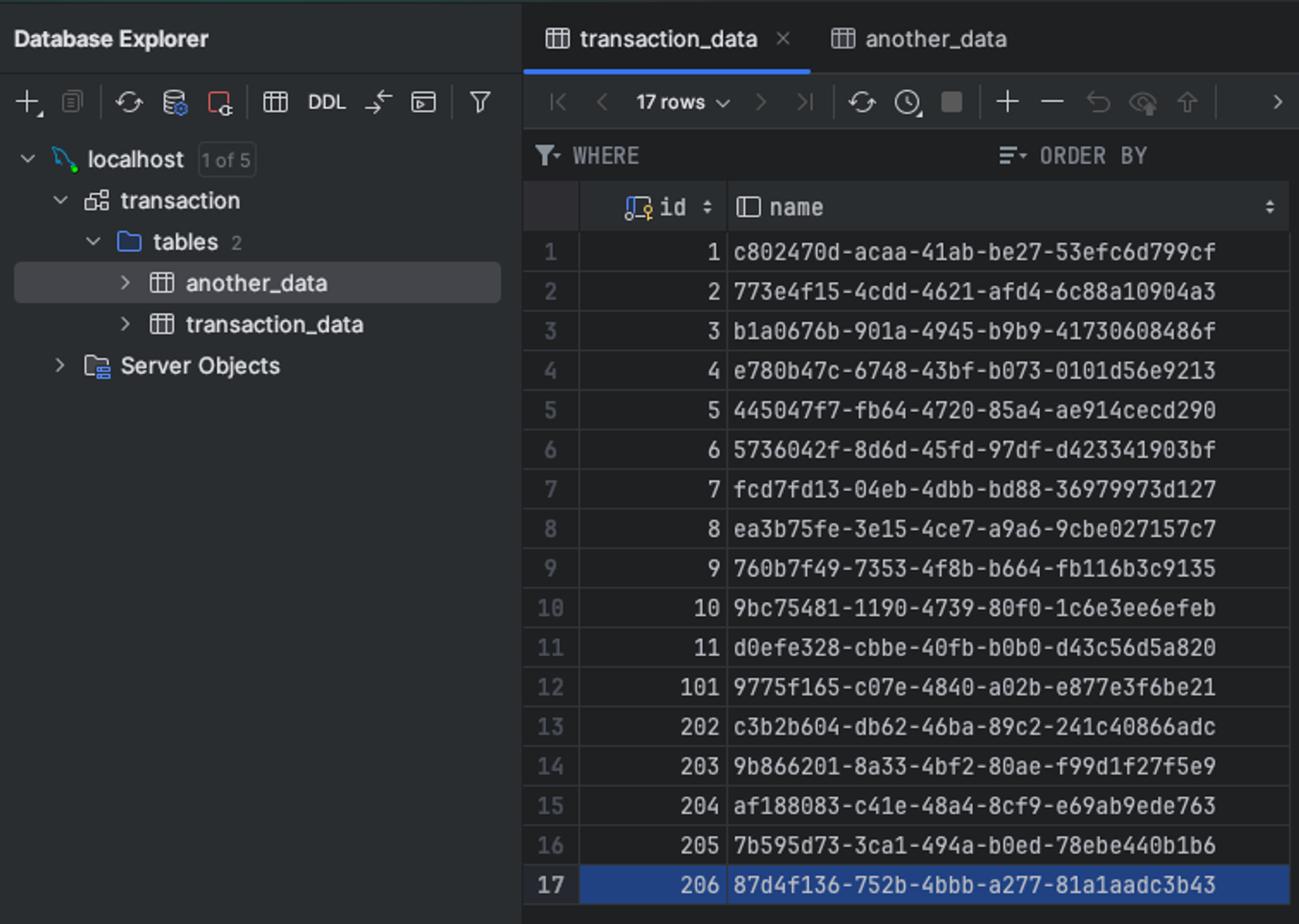
결론은 위에 있는 사진처럼 206으로 시작하게 됩니다.
Auto Increment의 동작 방식이 현재 있는 id 중 가장 큰 id를 기준으로 시작하게 된다는 부분이 문제가 됩니다
이렇게 되면 another_data의 6번 데이터를 잃어버리거나, 덮어씌워지게 됩니다
이렇게 해도 데이터가 없어지니 아주아주 큰일이 날 수 있죠
어떻게 하면 데이터를 완벽하게 살릴 수 있을까요?
아래와 같은 쿼리를 먼저 작동시킬 수 있습니다
alter table transaction_data
auto_increment = 401;이 쿼리를 사용하면 추가적으로 데이터들은 401번부터 쌓이게 됩니다
배치를 통해 모든 데이터를 다 옮기고 나면 아래와 같은 결과가 나오게 됩니다
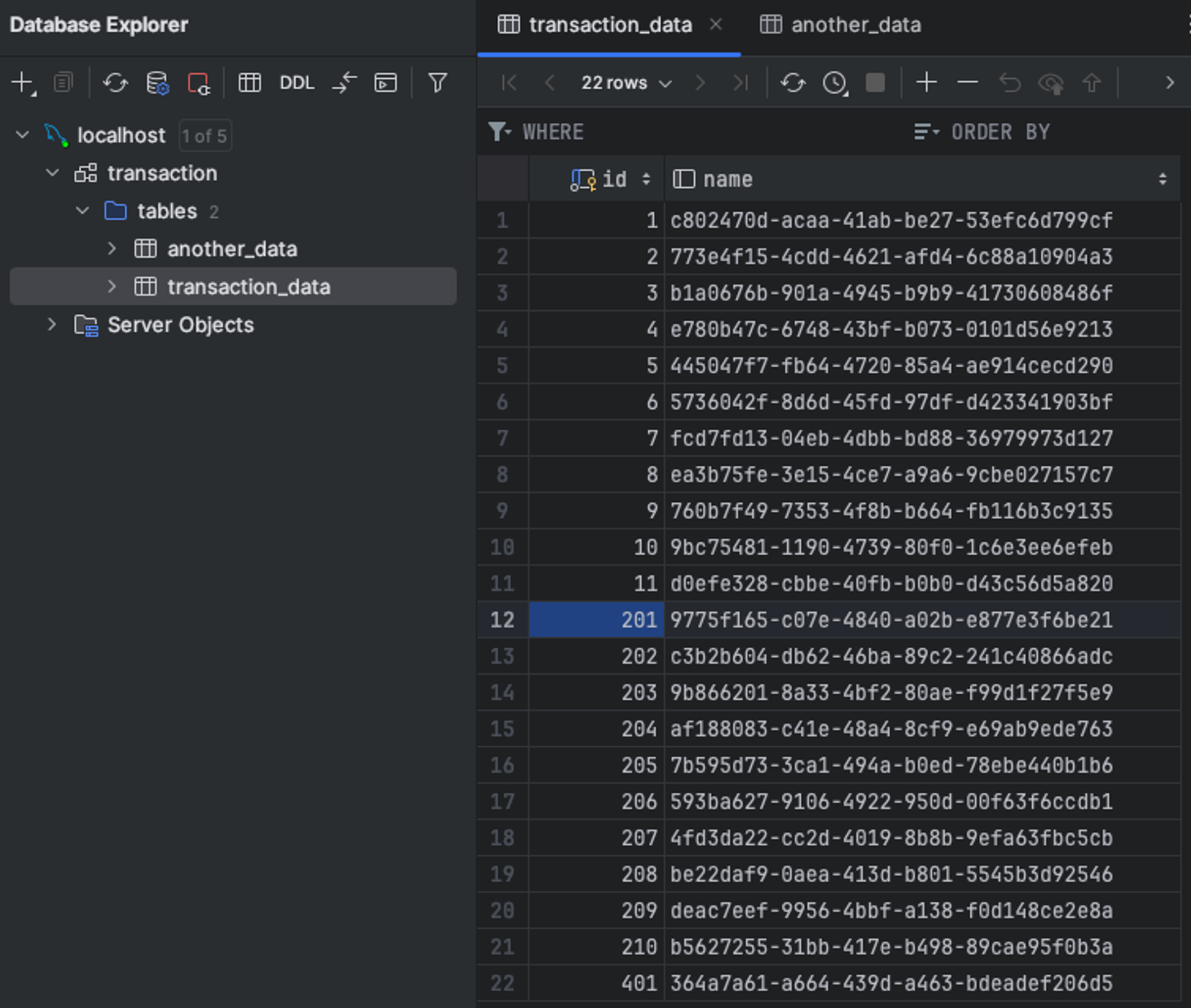
11번까지 transaction_data의 예전 데이터가 쌓이고
201부터 210까지 another_data의 데이터가 쌓이고
401부터 transaction_data 가 새롭게 쌓이게 됩니다.
이렇게 되면 어떤 문제가 있을까요?
id 순으로 봤을 때, 생성된 순서대로 정렬된 것이 아니게 됩니다.
이런 상황에서 만약 create_datetime 같은 것이 없다면, 그 정보를 복원할 수가 없겠죠
이런 상황을 대비해서 미리 create_datetime 같은 생성 시간 정보를 가지고 있는 것이 가장 중요합니다
긴 글 읽어주셔서 감사합니다
'Spring' 카테고리의 다른 글
| 여러분들은 동적 쿼리 어떻게 쓰시나요? (우리 팀에서Jpa Criteria 를 선택한 이유) (2) | 2023.12.24 |
|---|---|
| MDC 를 활용해 부가적인 정보를 남겨보자 (6) | 2023.12.03 |
| 공유 자원을 관리하는 bulk head에 대해서 알아보자 (8) | 2023.10.02 |
| 스프링에서 발생한 에러 로그를 슬랙으로 모니터링하는 방법 (1) | 2023.07.08 |
| Application Context vs BeanFactory (0) | 2023.05.02 |
문제 상황
같은 형태의 테이블 2개를 하나의 테이블로 합쳤을 때, Auto Increment 때문에 생길 수 있는 문제에 대해서 정리를 해보려고 합니다
편의를 위해서 정말 간단한 엔티티로 설명을 드리도록 하겠습니다
@NoArgsConstructor
@AllArgsConstructor
@Getter
@Entity
@Table(name = "transaction_data")
public class TransactionData {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(name = "name")
private String name;
public TransactionData(String name) {
this.name = name;
}
}이를 저장하는 코드는 다음과 같습니다
@RequiredArgsConstructor
@Service
public class TransactionDataService {
private final TransactionDataRepository transactionDataRepository;
public void save() {
var transactionData = new TransactionData(UUID.randomUUID().toString());
transactionDataRepository.save(transactionData);
}
}이 메서드를 통해서 저장을 하게 되면
아래와 같이 저장이 됩니다.
어느 날 다른 테이블의 데이터를 가져오라는 요구사항이 생겼습니다
그 데이터는 another_data라는 테이블입니다.
총 10개의 row 가 있는 transaction_data 와 같은 형태의 데이터인데요
column 이름은 편의를 위해서 모두 동일하게 만들었습니다
그냥 막 합쳐도 되지 않을까?
batch를 활용해서 another_data 테이블에서 데이터를 읽어오고, 그대로 transaction_data에 저장하면 되겠다라고 하면 큰일 납니다
중요한 데이터라면 바로 감옥에 갈 수도 있죠
문제의 원인은 another_data의 id와 transaction_data의 id 같다는 점입니다
id 가 겹치면, 기존 데이터가 덮어씌워지거나, 일부분의 데이터가 누락되게 됩니다.
처음 생각한 해결책
id 가 겹치는 것이 문제라면, 그만큼 여유분을 더해주고 시작하면 되겠다
트래픽이 오고 있어도, 200개 이상은 안될 테니 200개만큼의 여유분을 만들자
another_data의 id를 +200 해서, 1번을 201번으로, 2번을 202번으로 만들어서 transaction_data에 저장하자
저장이 다 끝나면 transaction_data의 id를 401부터 시작하도록 바꾸자
이렇게 작동하는 시나리오를 동작시켜 보도록 하겠습니다
한 번에 모든 작업이 이루어질 수는 없기 때문에 조금씩 옮길 텐데요
위와 같이 5개가 옮겨진 상황이라고 해봅시다
이때 transaction_data 테이블에 1개 추가 요청이 들어오면 어떤 id를 사용하게 될까요?
원래 기존의 데이터가 쌓이는 11에 이어서 12로 시작할까요?
아니면 205까지 있는 상황에서 206에서 시작할까요?
결론은 위에 있는 사진처럼 206으로 시작하게 됩니다.
Auto Increment의 동작 방식이 현재 있는 id 중 가장 큰 id를 기준으로 시작하게 된다는 부분이 문제가 됩니다
이렇게 되면 another_data의 6번 데이터를 잃어버리거나, 덮어씌워지게 됩니다
이렇게 해도 데이터가 없어지니 아주아주 큰일이 날 수 있죠
어떻게 하면 데이터를 완벽하게 살릴 수 있을까요?
아래와 같은 쿼리를 먼저 작동시킬 수 있습니다
alter table transaction_data
auto_increment = 401;이 쿼리를 사용하면 추가적으로 데이터들은 401번부터 쌓이게 됩니다
배치를 통해 모든 데이터를 다 옮기고 나면 아래와 같은 결과가 나오게 됩니다
11번까지 transaction_data의 예전 데이터가 쌓이고
201부터 210까지 another_data의 데이터가 쌓이고
401부터 transaction_data 가 새롭게 쌓이게 됩니다.
이렇게 되면 어떤 문제가 있을까요?
id 순으로 봤을 때, 생성된 순서대로 정렬된 것이 아니게 됩니다.
이런 상황에서 만약 create_datetime 같은 것이 없다면, 그 정보를 복원할 수가 없겠죠
이런 상황을 대비해서 미리 create_datetime 같은 생성 시간 정보를 가지고 있는 것이 가장 중요합니다
긴 글 읽어주셔서 감사합니다
'Spring' 카테고리의 다른 글
| 여러분들은 동적 쿼리 어떻게 쓰시나요? (우리 팀에서Jpa Criteria 를 선택한 이유) (2) | 2023.12.24 |
|---|---|
| MDC 를 활용해 부가적인 정보를 남겨보자 (6) | 2023.12.03 |
| 공유 자원을 관리하는 bulk head에 대해서 알아보자 (8) | 2023.10.02 |
| 스프링에서 발생한 에러 로그를 슬랙으로 모니터링하는 방법 (1) | 2023.07.08 |
| Application Context vs BeanFactory (0) | 2023.05.02 |